本稿では、再現性と費用対効果に優れた手法を用いて長文推論モデルを学習するためのオープンソーススイートであるLight-R1を紹介します。DeepSeek-R1シリーズで使用されるデータは独自のものであるため、公開データとモデルのみを活用する代替アプローチを開発しました。カリキュラム学習では、データの難易度を段階的に高め、多段階の学習後処理と組み合わせます。Qwen2.5-32BInstructで学習したLight-R1-32Bモデルは、数学的推論においてDeepSeek-R1-Distill-Qwen-32Bを上回る性能を発揮します。実験結果によると、このカリキュラムアプローチは、異なる学習段階で異なる多様なデータセットを利用できる場合に、より効果的になることが示されています。DeepSeekチームが独自のデータに基づいて事前調整したDeepSeek-R1-Distilledモデルを、カリキュラムデータセットの3,000個の難解な例で微調整したところ、最先端の7Bおよび14Bモデルが得られました。一方、32BモデルであるLight-R1-32B-DSは、QwQ-32BおよびDeepSeek-R1と同等の性能を発揮しました。さらに、GRPOを長文推論モデルに適用することで、研究を拡張しました。最終的なLight-R1-14B-DSは、数学において14Bモデルの中でSOTA性能を達成し、AIME24および25スコアはそれぞれ74.0と60.2となり、多くの32BモデルやDeepSeek-R1-Distill-Llama-70Bを上回りました。 Light-R1-14B-DS は、数学に重点を置いた学習にもかかわらず、強力なクロスドメイン汎化能力を発揮します。Light-R1 は、高度な推論モデルを実世界のアプリケーションでよりアクセスしやすく実装しやすくする上で、大きな進歩を遂げています。モデル、学習データ、コードは https://github.com/Qihoo360/Light-R1 で公開されています。
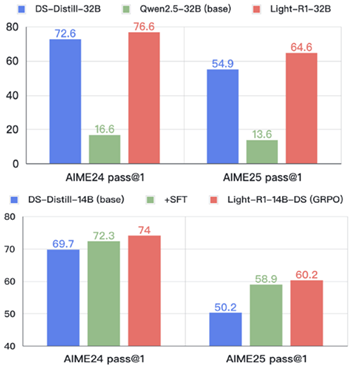
図1:再現可能な最先端のロングCOTモデル (上)ゼロから開発(ショートCOTベース)、 (下)カリキュラム学習戦略を用いてDeepSeek-R1-Distillモデルから派生 (ロングCOTベース)。
DeepSeek-R1 (DeepSeek-AI, 2025) のリリース以来、長い思考連鎖 (OpenAI, 2024; Wei et al., 2022; Kimi, 2025; Lightman et al., 2023) 推論は、基礎AIモデルと様々な産業AIアプリケーションの両方で広く普及しています。しかし、フルキャパシティのR1レベルモデル(通常700億以上のパラメータ、DeepSeek-R1では671億のパラメータ)を展開するには、法外な計算コストがかかります (DeepSeek-AI, 2025; Qwen, 2025)。巨大モデルの学習と展開にはリソースの障壁があり、エッジデバイスやリアルタイムアプリケーションには実用的ではありません。この制限により、数10億パラメータのコンパクトかつ高性能なモデルを開発し、長時間のCOTを実行できることへの関心が高まっています。これは、数学的問題解決、アルゴリズム計画、科学的分析にとって重要な要件です。この課題に対処するため、Light-R1シリーズに関する研究成果を紹介します。
本研究の基盤として、まず、DeepSeek-AI (2025) で報告された評価結果を厳密に再現する、堅牢で再現性の高い評価プロトコルを確立しました。この信頼性の高い枠組みを基に、革新的なアルゴリズムとエンジニアリングの進歩を通じて、3つの基本的な課題に体系的に取り組んでいます。
最初の課題は、長い思考連鎖最適化の重要な要素である学習後用の効率的なデータセットをキュレーションすることです(Ye et al., 2025; Muennighoff et al., 2025; Li et al., 2025)。数学的推論、論理的演繹、アルゴリズムによる問題解決など、多様なオープンソースの推論データを収集しました。重複を除去し、フォーマットを標準化するための前処理を行った後、DeepScaleR-1.5B-Preview(Luo et al., 2025b)とDeepSeek-R1-Distill-Qwen-32Bモデルを用いた2段階の難易度フィルタリング手法を実装し、合格率に基づいて難易度を定量化しました。
2つ目の課題は、このデータセットの活用を最適化する方法です。従来のアプローチでは通常、単一のSFTステージが採用されます(DeepSeek-AI, 2025; Xu et al., 2025; Labs, 2025; Yu et al., 2024)。しかし、32Bモデルを用いた予備実験では、重大な限界が明らかになりました。トレーニングデータの約20%は、10回の実行で依然として50%未満の合格率を示しており、異質な難易度のデータセットからの知識の同化が不十分であることが示されました。この問題を解決するために、私たちは、難易度が徐々に上昇する2つの連続するSFTステージと、それに続くDPOステージで構成される、多段階カリキュラムトレーニング戦略を実装しました(Rafailov et al., 2023)。最近の研究では、長い思考連鎖訓練のための様々なカリキュラム戦略が検討されています(Luo et al., 2025a; Min et al., 2024; Xi et al., 2024; Yuan et al., 2025a)。しかし、私たちのアプローチは優れた性能を示しています。Qwen2.5-32BInstruct(Qwen, 2024)から訓練されたLight-R1-32Bモデルは、数学的推論においてDeepSeek-R1-Distill-Qwen-32Bよりも優れた性能を発揮します。
3つ目の課題は、モデルのパフォーマンスをさらに向上させるために、学習後段階の最終要素である強化学習(Shao et al., 2024; Wang et al., 2024; Ouyang et al., 2022; Schulman et al., 2017, 2015)を実装することから生じます。Light-R1-14B-DSの強化学習学習に成功したことを報告できることを嬉しく思います。最近の研究では、基本モデル(Zeng et al., 2025; Hu et al., 2025; Liu et al., 2025)、小規模モデル(Zeng et al., 2025; Luo et al., 2025b)、あるいは集中的な計算リソースを用いた大規模モデル(Qwen, 2025)の学習において成功が示されていますが、我々のlong-COT RLの学習後処理は、long-COT 14Bモデルにおいて、通常観察される初期の長さの短縮なしに、応答長と報酬スコアの両方が同時に増加することを初めて実証したものです。この画期的な成果は、慎重に設計されたカリキュラム戦略によって、小規模モデルにおける強化学習のこれまで報告されていたスケーラビリティの限界を克服できることを示しています(Gao et al., 2023)。
本研究の主な貢献は以下のとおりです。
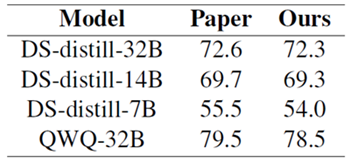
表1:AIME24 (MAA, 2024) pass@1におけるDeepSeek-AI (2025)とQwen (2025)の評価結果の再現。64回実行の平均。
DeepSeek-AI (2025) に倣い、long-COT モデルはサンプリング温度 0.6 で一般的に導入されています。long-COT モデルは一般的に、貪欲デコードよりもサンプリングを用いた方がパフォーマンスが向上しますが、評価のための貪欲デコードのこれまでの有効なアプローチ (Song et al., 2024) とは異なり、各質問に対して複数のサンプルが必要になる場合があるため、モデル評価の負担が大きくなります。
DeepSeek-AI (2025) は、pass@1 を推定するためにクエリごとに64個のレスポンスを生成します。この選択を検証した結果、同じモデルを複数回実行した際に16個以下のレスポンスで3ポイント以上の大きな偏差が確認されました。このようなランダム性は、モデルのパフォーマンスを比較する上で許容できません。
安定的かつ信頼性の高い評価を行うため、全ての評価実行において (Luo et al., 2025b) の評価コードを採用しました。評価コードとログはすべて公開されています。
DeepSeek-AI (2025) および Qwen (2025) で報告されているすべての DeepSeek-R1-Distill モデルと QwQ のスコアを、表 1 に示すように、クエリあたり 64 サンプルで約 1 ポイントの偏差で再現できます。
数多くの研究(Ye et al., 2025; Muennighoff et al., 2025; OpenThoughts, 2025; OpenR1, 2025)では、15億から32億までの様々な規模のモデルを用いてDeepSeek-R1を再現するオープンソースの取り組みが行われていますが、難易度の高い数学コンテストAIME24と25でDeepSeek-R1-Distill-Qwen-32Bがそれぞれ72.6と54.9というスコアを記録したのに対し、同様のパフォーマンスを達成した研究は存在しません。
このセクションでは、図2に示すように、データ処理と学習後のパイプラインを示します。
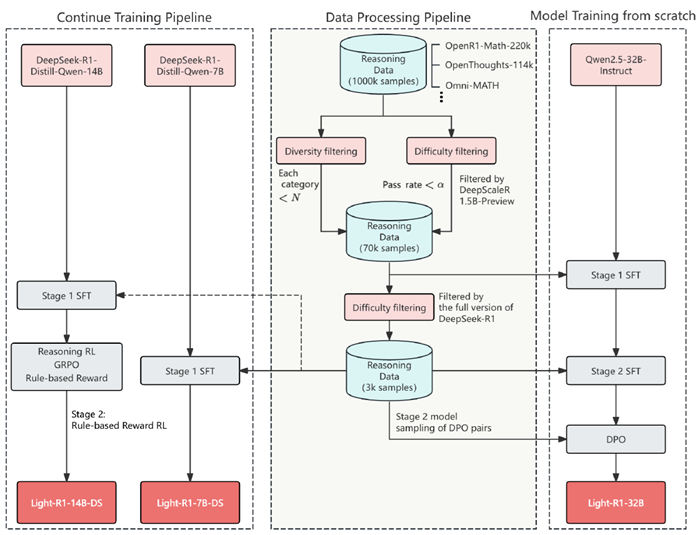
データ準備プロセス全体は、データ収集、データ除染、データ生成から成り、以下に詳しく説明します。
まず、グラウンドトゥルースの解答を持つ数学の問題を様々なソースから収集しました。あらゆるソースを反復処理した結果、シードセットとして約100万問の数学の問題が収集されました。データソースの詳細については、付録Aをご覧ください。
すべてのデータは集約され、シードセットとして約100万問の数学問題が作成されます。この100万問のデータのうち、グラウンドトゥルース解答を持つ数学問題のみを保持しました。グラウンドトゥルース解答を持たない問題は、複数の強力なLLMにグラウンドトゥルースを投票させることで合成データとして使用できますが、これは将来の研究のために残しました。
次に、データは多様性を考慮してフィルタリングされ、社内のタグ付けシステムを使用して各質問にタグが付けられ、過剰なデータを含むカテゴリがダウンサンプリングされます。
複数のオープンソースデータセットにおけるデータ汚染を評価しました。分析の結果、MATH-500 (Hendrycks et al., 2021a) には、数値が同一であるか、または数値のみが異なる、数十の不適切な問題が含まれていることが明らかになりました。AIME 24および25は汚染されていませんが、2023年までのAIMEデータを組み込む際には注意が必要です。詳細は付録Bに記載されています。
Light-R1は、完全一致マッチング(数字を除外し、数値のみの変更がある質問をフィルタリング)とAIME24&25、MATH-500、GPQA(Rein et al., 2023)とのNグラムマッチング(N=32)を用いて、包括的な除染を受けました。
多様でクリーンなデータセットを用いて、教師ありファインチューニング(SFT)のための包括的な思考連鎖(COT)応答を生成します。しかし、すべてのデータポイントがトレーニングにおいて同等に価値があるわけではなく、DeepSeek-R1の抽出には、APIクエリ経由かローカルデプロイメント経由かを問わず、多くのリソースを消費する可能性があります。そこで、長推論モデルのトレーニングにおける最近の進歩(Luo et al., 2025b; Ye et al., 2025; Muennighoff et al., 2025)に着想を得て、データセットに難易度ベースのフィルタリングを実装し、十分に難しい質問のみを保持しました。
各質問に対する回答生成には、まずLuoら (2025b)のDeepScaleR-1.5B-Previewモデルを採用しました。このモデルは効率性と機能性のバランスに優れています。DeepSeek-R1クエリには、合格率がα未満の質問のみが選択されたため、約76,000のデータポイントが得られました。DeepSeek-R1の回答を取得した後、COT長文正解がある質問のみを保持しました。複数の正解がある質問については、SFT用にCOT長文正解をランダムに1つ選択しました。このプロセスを通じて、多様性と難易度の両方でフィルタリングされたプロンプトと、DeepSeek-R1によって生成され、正解データと照合されたCOT長文解答を含む、70,000例を超えるSFTデータセットを構築しました。
しかし、このデータセットのみを直接学習させた場合、学習エポック数に関わらず満足のいく結果は得られませんでした。学習済みモデルのパフォーマンスを様々な質問タイプで分析した結果、より難しい問題で追加の学習を行う必要があることがわかりました。そのため、DeepScaleR-1.5B-Previewではなく、DeepSeek-R1のフルバージョンを使用して、難易度フィルタリングの第2段階を実装しました。この段階では、合格率がα未満の質問と、DeepSeek-R1のサンプル回答が一様に正解でも一様に不正解でもない質問のみが保持され、約3,000例からなる第2段階のSFTデータセットが生成されました。注目すべきは、この改良されたデータセットは非常に高品質であり、このデータセットのみで学習させることで、すべてのDeepSeek-R1-Distillモデルのパフォーマンスが向上したことです。これについては、第3.4節で説明します。
私たちのアプローチは3つの段階から構成されており、詳細なハイパーパラメータは付録Cに記載されています。
SFTステージは、3.1.3節で説明したカリキュラムデータ戦略を用いて学習されます。DPOについては、NCA損失(Chen et al., 2024)を用いた半方策アプローチを実装しました。拒否された応答は、検証済みの誤答を含むSFTステージ2モデルからサンプリングされました。拒否された応答の中には32,000トークン以上の長さに達するものもあったため、360-LLaMA-Factory(Zou et al., 2024)のシーケンス並列性を備えたDPO実装を利用しました。選択応答については、DeepSeek-R1の検証済みの正解を使用しました。以前は完全方策DPOを広範囲に使用していましたが、難しい数学の問題では、より強力なモデルからの選択応答を使用することで、より良い結果が得られることを発見しました。
カリキュラムSFTとDPOの訓練後段階全体を通して、一貫した改善が見られました(表2)。DPOの後、Goddard et al. (2024) ツールキットのTIES-merging(Yadav et al., 2023)手法を用いて、SFT-stage2、DPO、そして不採用となった回答から誤って特殊トークンが削除された別のDPOバリアント(AIME24スコア:74.7)のモデルを統合しました。その結果得られた統合モデルは、さらなるパフォーマンス向上を示しました。数学に重点を置いた訓練により、訓練されていないGPQAの科学的質問では多少の忘却が生じましたが、Light-R1-32Bは依然として高い一般化能力を示しています。
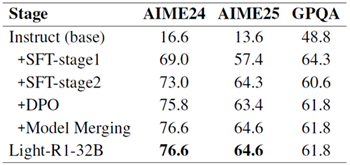
表2:Light-R1-32Bの段階的なパフォーマンス向上。STF-stage2以降、GPQA(科学QA)スコアの低下が見られ、数学に重点を置いた広範なトレーニング中にモデルの汎化能力が部分的に低下したことを示しています。しかしながら、Light-R1-32Bはベースモデルと比較して依然として高い汎化性能を示しています。
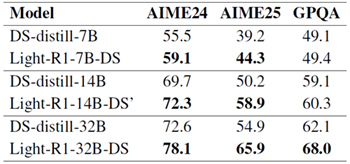
表3:SFTステージ2の3Kデータの有効性。 おそらく我々のモデルとは直交するデータセットを活用している、より強力なベースモデルを微調整することで、あらゆるモデルサイズにおいて一貫してパフォーマンスが向上します。「Light-R1-14B-DS」という表記は、最終的なLight-R1-14B-DSモデルのSFTのみのバージョンを指し、その後、GRPO RLトレーニングの追加ステージが行われます。
DeepSeek-R1-Distill-QwenモデルをSFTステージ1の強化版と見なし、3Kのステージ2データを用いてDeepSeek-R1-Distill-Qwenモデル上にSFTステージ2を実行しました。
驚くべきことに、表3に示すように、この3kデータだけでDeepSeek-R1-Distill-Qwenモデルの普遍的な改善を達成することができ、ステージ2データの品質の高さを実証しました。また、この3kデータはDeepSeek-R1-Distill-Qwenモデルの800k SFTデータとある程度直交しているため、このような改善が容易になったとも考えられます。
Light-R1-32B-DSは、科学分野とコード分野におけるドメイン固有のトレーニングが欠如しているにもかかわらず、GPQAの性能が予想外に高く、より強力なベースモデルはより強力な一般化能力の恩恵を受ける可能性があることを示唆しています。対照的に、Light-R1-7B-DSは、同一のデータカリキュラムでトレーニングされているにもかかわらず、ドメイン内タスクのみに限定された改善を示しています。
強化学習の実験は、DeepSeek-R1-Distill-Qwen-14Bを用いて行いました。私たちの知る限り、これは、既に長期間使用されているCOT 14Bモデルにおいて、強化学習によってパフォーマンスが大幅に向上したことを実証した、初めて公に文書化された研究です。
DeepSeek-AI (2025)、Yuan et al. (2025b)、Zhang et al. (2025) によるこれまでの研究では、320億パラメータ以下の小規模モデルでも、大規模な推論モデルからの蒸留によって高い性能レベルに到達できることが示されています。しかし、すでに長時間のCOTで微調整されたモデルに対する強化学習(RL)によるさらなる改善は、コミュニティではまだ広く普及しておらず、ゼロRL(第1節)ほど容易には達成できません。Luo et al. (2025b) は、小規模モデルDeepSeek-R1-Distill-Qwen-1.5Bで有望なRLトレーニングを実証しましたが、同じレシピを使用して、より大規模なDeepSeek-R1-Distill-Qwen-14Bモデルで同様の結果を再現する際に課題に直面しました。
数週間にわたる調査を経て、私たちは効果的なカリキュラムSFTの試みとCuiら (2025) を参考に、2パスプロセスで構成される最終的な強化学習ソリューションに到達しました。プロセスは以下のとおりです。
私たちの観察では、オフラインデータ選択が重要な役割を果たしています。これは、簡単すぎる、または難しすぎるプロンプトを除外し、トレーニングデータがルールベースの回答検証ツールと一致することを保証します。合格率0のデータを手動でチェックしたところ、プロンプトの回答の半分以上が検証不能(テキストまたは複雑な条件式が含まれているため)か、誤りであることがわかりました。難易度推定モデルとしてLight-R1-7B-DSを使用しました。これはより効率的であり、pass@64の点で大規模なモデルと同等のパフォーマンスを示すためです。さらに、合格率0のデータを再チェックするためにモデル検証ツールを使用しました。誤検証されたデータを除外することで、将来のカリキュラム強化学習において難しいプロンプトを正確に特定できます。
最適化アルゴリズムとしてGRPO (Shao et al., 2024) を選択し、Verl (Sheng et al., 2024) に基づいて実装しました。また、強化学習プロセスを安定化するために、短い正解に対する選好度を弱めた長さ報酬の修正版 (Yeo et al., 2025) と、重要度サンプリング重みクリッピング (Mini-Max, 2025) という2つの手法を採用しています。
長さの制御については、(Yeo et al., 2025) が提案したアプローチの改良版を採用します。具体的には、回答が正解の場合に短縮報酬を切り捨てることで、初期の長さの短縮を防ぎます。この手法は、学習中に適切な回答の長さを維持し、学習プロセスの初期段階でモデルが応答を過度に短縮しないようにするのに役立ちます。
重要度サンプリングの重みクリッピングに関しては、より広範な両側クリッピング機構を実装します。 これまでの観察結果から、時折、大きな正のポリシー比率と負のアドバンテージが組み合わさると、損失の急増につながり、ポリシー最適化を阻害する可能性があることが示されています。この両側クリッピング手法は、MiniMax (2025) で報告された知見と並行して、以前の実験でも実装されています。重要度サンプリングの重みをクリッピングすることで、極端な値の影響を制限し、学習プロセスをより安定させることができます。
ルールベースの報酬とBig-Mathデータセット(Albalak他 (2025))の重複排除版を使用します。実験は16 x 8のA100 GPUクラスターで実施しました。オフラインのデータ選択プロセスには4時間かかり、オンライン強化学習は140ステップの完了に26時間、220ステップの完了に42時間かかりました。
図3からわかるように、RLトレーニングは期待通りの挙動を示し、応答長と報酬スコアが同時に増加しています。開始時に注目すべき長さの減少は見られません。3エポックのトレーニングを終えた後、RLエポック1と2を評価しました。表4に示すように、最初の2エポックでは大きな改善は見られませんが、健全なRLトレーニング曲線はトレーニングを継続する自信を与えてくれます。Light-R1-14B-DSは最終的に約3エポック、つまり220ステップのRLトレーニングを受けました。
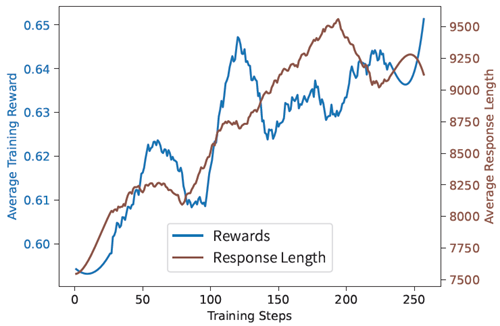
図3:Savitzky-Golayフィルタで平滑化された、応答長と訓練報酬のRL学習曲線。
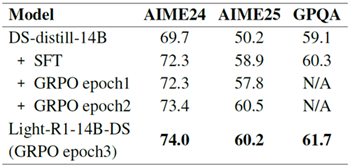
表4:Light-R1-14B-DSの強化学習性能の向上。特に、GPQAにおいて領域外の改善が見られ、数学に重点を置いたデータセットにおける強化学習が、多様な領域にわたる一般化を促進する可能性があることを示唆しています。
Light-R1シリーズは、リソース制約下での長時間推論モデルの学習という課題に取り組んでいます。カリキュラム学習戦略を用いて、長時間COTモデルをゼロから学習することに成功しました。厳選された3Kデータセットは、様々なモデルサイズ間で優れた移植性を示し、DeepSeek-R1-Distillモデルを大幅に強化し、7B、14B、32Bのパラメータを持つモデルの新たなパフォーマンスベンチマークを確立しました。さらに、強力な多段階微調整ベースモデルに強化学習を適用した場合の有効性を調査し、学習プロセス全体を通して安定した応答長の増加を維持しながら、優れたパフォーマンスを実現しました。
これらの進歩は、R1レベルの推論機能へのアクセスを民主化するだけでなく、長期推論モデルのカリキュラム設計、データ効率、RLのスケーラビリティに関する貴重な洞察も提供します。私たちのオープンソースモデル、データセット、そしてコードは、特にリソースが限られたアプリケーション向けに、コンパクトでありながら強力な推論システムの開発研究を加速することを目的としています。今後の研究では、長期推論モデル向けの強化された一般化機能の統合と、RLトレーニング効率のさらなる最適化を検討します。
表5:公開データの構成。ここでは、第一段階の多様性と難易度によるフィルタリング後のデータ構成をまとめています。異なるソースには重複する例が含まれている可能性があります。そのため、初期のシードデータセットとしてOpenR1-Math-220kを使用しています。これが、このソースがデータの大部分を占めている理由です。
| ソース | 説明 | サンプル数 |
|---|---|---|
| OpenR1-Math-220k (OpenR1,2025) | 2~4つの推論要素を含む数学問題 NuminaMath 1.5の問題に対してDeepSeek R1で生成されたトレース。 | 58224 |
| OpenThoughts- 114k (OpenThoughts, 2025) | 数学、科学、コード、パズルを網羅した11万4千件の高品質な例を含む、オープンな合成推論データセット | 14214 |
| OpenMathInstruct-2 (Toshniwal et al., 2024) | Llama3.1-405B-Instructモデルを使用して生成された Nvidiaによる数学命令チューニングデータセット | 1786 |
| OmniMath (Gao et al., 2024) | コンテストの数学の問題 | 567 |
| s1K-1.1 (Muennighoff et al., 2025) | 多様で高品質、そして難解な問題 DeepSeek-R1から抽出された推論の痕跡と解答付き | 346 |
| LIMO (Ye et al., 2025) | LIMO論文からの3段階フィルタリングデータ | 246 |
| hendrycks-math (Hendrycks et al., 2021b) | 12,500問の難解な数学競技問題。各問題にはステップバイステップの解答が用意されており、解答の導出と説明を生成するモデルを学習する際に役立ちます。 | 179 |
| Ours | 社内数学データセット | 3877 |
| Total | 上記のデータセットと推論のトレースおよび解決策を組み合わせたもの | 79439 |
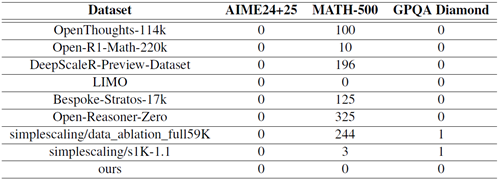
表 6: オープンソース データセット内のベンチマークに一致したプロンプトの数。
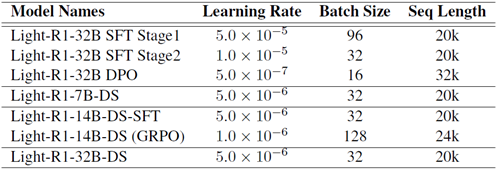
表7:Light-R1シリーズの学習ハイパーパラメータ。シーケンス長は学習データの特性によって決定されますが、GRPOは例外で、ロールアウト計算コストの最小化、推論カットオフ比の低減、32kコンテキスト評価性能の最適化など、複数の要素のバランスを考慮します。32kコンテキスト長のDPOを学習する際のGPUメモリの制限を克服するため、360-LLaMA-Factory (Zou et al., 2024) のシーケンス並列処理を備えたDPO実装を利用します。「-DS」サフィックスが付いたモデルはDeepSeek-R1-Distill-Qwenシリーズから派生したもので、その他のモデルはQwen2.5-32B-Instructシリーズから派生したものです。